EdTech AI tools make bold promises. They'll differentiate for you. They'll match your standards. They'll generate reading at the exact grade level you request.
But here's a question most schools never ask: does the output actually land where the tool says it does?
We ran a small test to find out, and the results were eye-opening.
The Problem Nobody Is Testing
AI-generated instructional content is flooding classrooms. Tools promise grade-level accuracy, standards alignment, and pedagogical quality. Teachers trust the label on the box because, honestly, who has time to run a readability calculator on every passage the AI spits out?
But trust without verification is risky. If a teacher asks for a grade 5 reading and gets grade 8 prose with shorter paragraphs, the differentiation promise falls apart. Students who needed accessible text still can't access it. The teacher still has to rewrite. And the time savings everyone was sold on? Gone.
The deeper issue is this: most AI tools treat grade-level targeting as a prompt instruction, not an engineering problem. They tell the language model "write at a 5th grade level" and hope for the best. We decided to go further, building in actual calibration systems that shape the output.
A Simple Test Reveals a Big Gap
To illustrate the point, we took three popular tools, QuestionWell, Gemini and MagicSchool, and ran a straightforward experiment. We asked each to generate informational reading passages at five specific grade levels (3, 5, 7, 9, and 11) on common school topics: pollination, the water cycle, plate tectonics, photosynthesis, and the causes of the French Revolution.
Then we scored every output with the same independent readability calculator (Flesch-Kincaid) so neither tool got the home-court advantage of its own scoring system.
The results:
| Tool | Mean Absolute Error (grade levels) | Consistent Direction? | Within 1 Grade Level |
|---|---|---|---|
| QuestionWell | 1.26* |
Mixed (some above, some below) | 3 of 5 |
| MagicSchool | 4.72 | Always above target | 1 of 5 |
| Gemini | 1.42 | Mixed (Some above, some below) | 1 of 5 |
* We used our Elementary Reading tool for 3rd Grade and Generate Student Reading for the other grade levels.
QuestionWell averaged less than two grade levels off target. Gemini was a close second by the average, but it's accuracy is just one in five. MagicSchool averaged nearly five, and it overshot every single time. Systematically.
When It Goes Wrong, It Really Goes Wrong
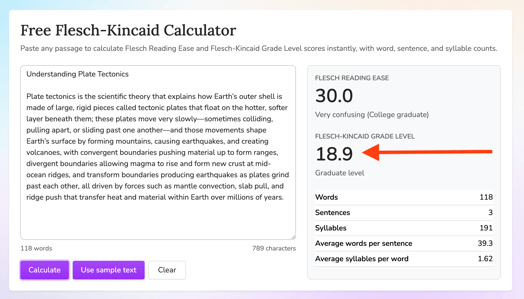
The most dramatic example: grade 7, plate tectonics.
QuestionWell produced a passage that scored at 7.3 on the Flesch-Kincaid scale. Right on target.
MagicSchool's version? 18.9. That is not a typo. It produced a single 118 word sentence. It read closer to a graduate seminar than a middle school classroom.
This is a useful reminder that readability is not just about vocabulary. Sentence structure alone can push a passage far beyond its intended audience. And if the tool is not actively engineering for sentence-level control, these kinds of misses are inevitable.
What This Means for You
This is a story about what can happen when schools adopt AI without asking hard questions about output quality.
Here is what we'd recommend asking any edtech AI vendor:
- "How do you calibrate grade-level output?" If the answer is "we prompt the model," that is a red flag. Look for tools that have built engineering systems around accuracy, not just prompt wrappers.
- "Can I verify your output with an independent tool?" Any vendor confident in their quality should welcome third-party measurement. If they discourage it, ask why.
- "What does your error rate look like across grade bands?" A tool that works great at grade 9 but misses badly at grade 3 is not reliable for differentiation. Ask for data, or run your own checks.
- "Does the output consistently skew in one direction?" Consistent overshooting (like what we saw in this test) suggests a systemic issue.
The Bigger Picture
AI in education is moving fast, and the pressure to adopt is real. But speed without quality checks means teachers end up spending just as much time fixing AI output as they would have spent creating from scratch. Over time, they lose trust in the tools in the process, and may stop using the tool altogether.
The schools that will get the most value from AI are the ones that treat quality verification as part of the adoption process. Run your own tests. Use independent metrics. Compare what the tool promises to what it actually delivers.
In our test, QuestionWell was not perfect, but across five passages, it had the lowest average error and highest accuracy rate of the three tools.
That kind of calibration does not happen by prompting alone. It happens when a team treats grade-level accuracy as an engineering challenge worth solving, because teachers who ask for grade 5 text deserve grade 5 text. We continually benchmark our tools and they're always being improved.
Try It Yourself
The best way to evaluate any tool is to test it with your own content and your own standards. QuestionWell's free Flesch-Kincaid calculator is available to everyone, and you can use it to score output from any AI tool, including ours.
We think that is how it should work. If a tool is doing its job, measurement is not a threat. It is proof.
This test used five from-scratch informational passages per tool, scored with the same Flesch-Kincaid calculator.



