I'm excited to announce a new beta feature in QuestionWell: Roster Sync with Clever. QuestionWell...
Writing good multiple-choice questions (MCQs) is well studied and well known to be difficult, even for human beings. Decades of research document common flaws: inadvertently giving students cues, implausible distractors, ambiguity, and questions that reward test taking strategies, and allow students to side-step understanding. Large language models (LLMs) make many of the same errors as human question writers.
At QuestionWell, we push our AI to do better. This fall, we trained our AI model specifically to reduce well-documented item writing flaws in multiple choice questions. No AI will be 100% perfect 100% of the time, but we can now compare the quality of multiple choice questions generated by our model as compared to other models. Now, we can offer our users the best model possible, and know exactly how good it is.
Background
Previous research has identified a small set of item writing flaws (IWFs) that commonly occur in multiple choice questions [1, 2]. Common examples include:
-
Cueing effects, where the correct answer stands out (e.g., it is longer, more specific, or more precise than distractors)
-
Implausible or heterogeneous distractors that can be eliminated without understanding the content
-
Absolute terms (“always,” “never”) that unintentionally signal correctness or incorrectness
-
Grammatical or semantic mismatches between the stem and answer choices
These flaws matter because they allow students to answer correctly using test taking strategies rather than by using the targeted knowledge or skill. Even a single flaw can meaningfully distort item difficulty and effectiveness, so it's best to avoid them altogether.
Which factor most directly influences enzyme activity?
A. Light exposure
B. Surface area
C. Molecular size
D. Temperature of the surrounding environment
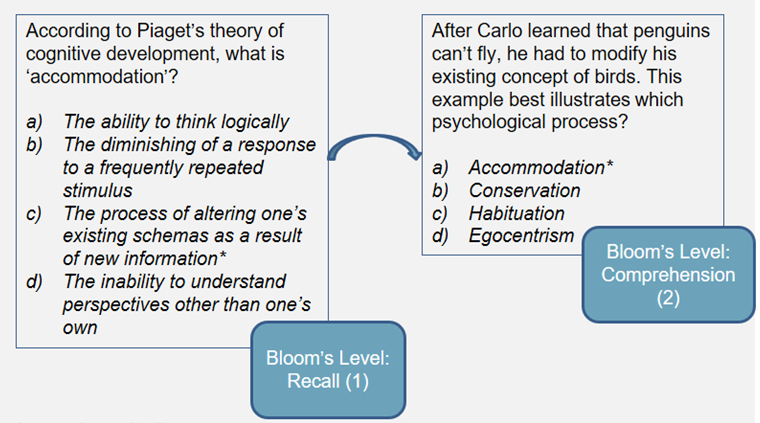
The correct answer in this example is longer and more complex than the other three options. A student can easily guess D if this pattern appears repeatedly—without ever learning anything about enzymes.
How AI Models Stack Up on Item Writing Flaws
We noticed that the LLMs we were using were making many of the same mistakes that humans made while writing multiple choice questions based on a text. So, here's what we did:
- First, we set up an automated rubric to check a given quiz for each of these item writing flaws:
- Longest answer choice is correct (an example of cueing)
- Has absolute terms (such as "always" and "never")
- Fill in the blank (instead of multiple choice)
- True/false (instead of multiple choice)
- Has "all of the above" or "none of the above" as an answer choice
- Then, we trained a model to avoid the above flaws, making sure we didn't accidentally change these other attributes in the process:
- How similar the question is to the text it is based on
- Lexile level score
- Number of Questions
- Learning Outcome Alignment
- Distribution of Questions on Bloom's Taxonomy
- Finally, we generated 50 quizzes using the same prompt, and checked each question for each flaw.
So what did we find?
The first chart shows average question set quality. We automatically "grade" each quiz on a scale from 0 to 1 by applying a penalty for each flawed question. So, a question set with a score of 0 would contain exclusively flawed questions, while a question set with a score of 1 would contain no flawed questions. QuestionWell's model produced, on average, quizzes that were 96% unflawed.

If we turn this into traditional school "grades", QuestionWell scores an A, while Gemini 2.5 flash gets a D+ and GPT 4.1 nano gets an F. So, our model scores higher overall, but averages only tell part of the story.
Now, let's break down both 1) how often quizzes are flawed, and 2) how severe their flaws are.
In this graph, we categorized quizzes produced by each model into buckets, based on the minimum percentage of questions in a quiz that are unflawed. Each point shows how many quizzes from a given model meet or exceed that accuracy level. As the buckets become more demanding, the number of qualifying quizzes drops—revealing clear differences in how consistently each model avoids flaws in quizzes. We can see from the graph that GPT 4.1 nano drops off first, and Gemini 2.5 flash drops off next. The new QuestionWell model does drop off once we get to over 90%, but before that it is remarkably consistent.

Conclusion
We believe that AI should improve the quality of instructional materials in classrooms, not provide teachers with slop. As an EdTech company, we need to be providing teachers with the best possible AI models to work with. When it comes to question flaws, consistency matters.
For teachers, this means less time reviewing and fixing questions, and greater confidence that student performance reflects understanding rather than test-taking skill. This new model will be available FREE to ALL QuestionWell users in the coming weeks, since we believe everyone should have great questions.
Limitations and scope. This analysis uses a relatively small sample (50 outputs per model) of English-language MCQs and assesses only some item writing flaws. Results should be interpreted as evidence of the measured constructs, not a comprehensive evaluation of all question quality dimensions, although future improvements will work toward greater comprehensiveness.

.jpeg?height=200&name=images%20(1).jpeg)